

목적
어떤 기업에서 빅쿼리를, 왜 도입해야하는지 소개합니다.

빅쿼리가 필요한 경우
Google 스프레드시트로 대량의 데이터 분석을 하다보면, 한계에 이르게 됩니다. 스프레드시트 자체에 셀 제한이 있기 때문인데요. 구글에서 최대 5백만개라고 제시하고 있습니다. (Google 드라이브에 저장할 수 있는 파일 참조)
5백만개면 일반 회사에서는 충분합니다. 좀 부족해지면, 파일을 또 만들면되지요. 하지만 쇼핑몰을 운영하거나, 보험계약 관리의 경우처럼 데이터를 연속적으로 많이 처리해야하는 경우는 이야기가 달라집니다.
1. 데이터의 통합관리
몇 년 전 분석한 매출액이 10억원 전후 정도의 작은 쇼핑몰만해도 월 1만행의 판매/수집 데이터가 생성됩니다. 열은 20개 정도라고 보면, 월 20만 셀을 사용합니다.
물론 5백만개를 채우려면 이론적으로는 25개월의 데이터를 넣어야 하겠지요. 하지만, 분석을 하기 위해 쿼리를 사용하고, 추가적인 작업을 진행해야하기 때문에 1년 반 정도의 데이터만을 넣을 수 있습니다.
최근에 빅쿼리를 도입해서 데이터스튜디오 분석을 진행하신 보험관련기업도 월 5천건 이상의 계약 데이터가 생성되는데, 열은 30개가 넘었습니다. 다양한 연산도 필요해서 2022년부터는 6개월마다 파일을 하나 생성해야하는 상황이 되었습니다.
두 기업 모두, 데이터를 통합해서 분석하고 데이터스튜디오와 같은 시각화 툴로 보려면 빅쿼리의 도입이 필수적이었습니다.
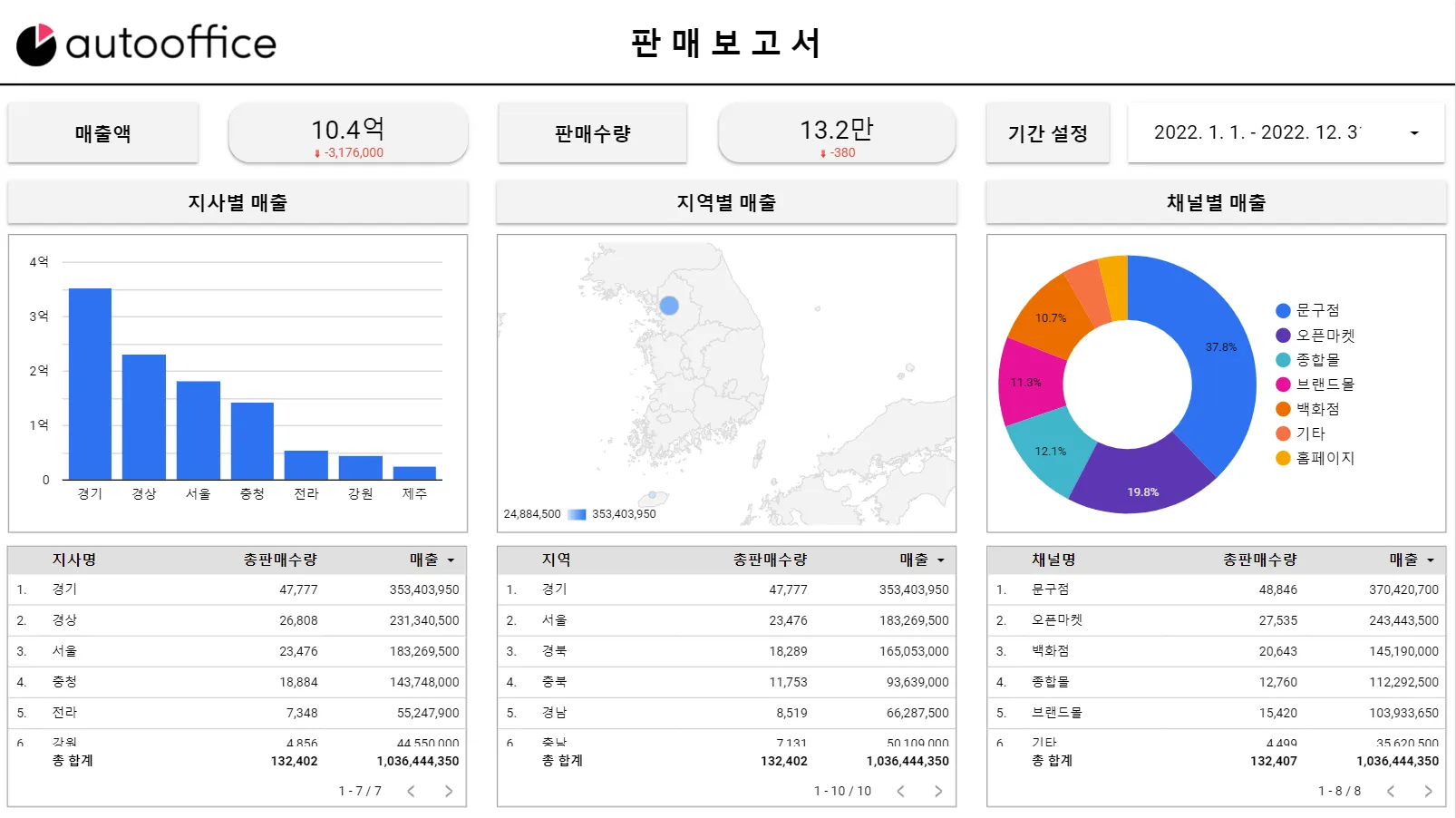
2. 속도 이슈
속도도 문제가 됩니다. 구글 시트의 처리 속도는 PC의 성능에 좌우됩니다. 클라우드 서비스이지만... 노트북보다는 데스크탑이 훨씬 빠르게 연산을 하고, 분석을 할 수 있습니다.
그런데 클라이언트분들 중에는 외근을 하며 노트북으로 구글 시트에 접속하시는 분들도 있고, 데스크탑이 최신형이 아닌 경우도 있어서 구글 시트를 연차별로 가볍게 만드는 방법을 사용합니다.
보통 매입, 매출, 품목, 통장 등 10개 내외의 시트를 사용하면서 50만셀 정도 사용하니 노트북에서는 버벅이기 시작합니다.

3. 오류 방지
이렇게 세팅을 하면, 연차별 시트에서 데이터를 IMPORTRANGE 로 불러와서 쿼리로 분석해야 하는데 문제가 있습니다. 구글 시트에서 많은 양의 데이터를 IMPORTRANGE 하면, 종종 내부 오류라며 실패합니다.
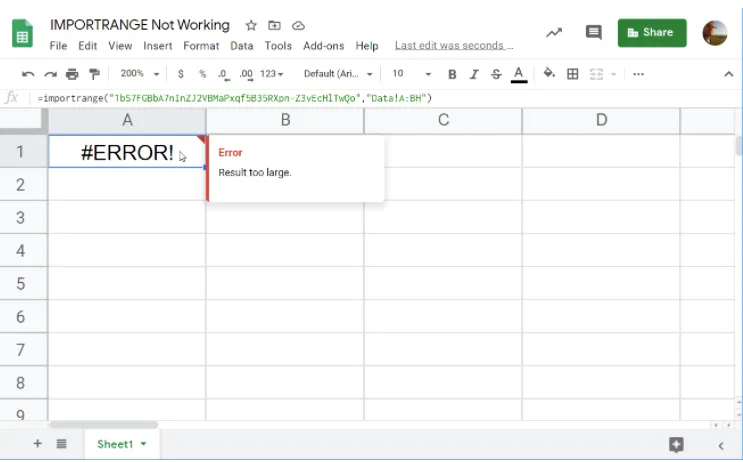
해외 사이트들에서도 이 점에 대해 많은 좌절 리포트들이 있는데, IF, ISERROR 를 사용해서 여러 번 데이터를 호출 방법이 사용되지만, 완벽한 해결책은 아닙니다.
분석 결과를 시각화할 때 datastudio 를 사용하는데, 소스로 사용하는 구글 시트에서 IMPORTRANGE 로 인해 오류가 나면, 시각화 자료가 표시되지 않아 문제가 됩니다.
개인적으로 사용하는 거면, 좀 이따가 접속해보면 정상으로 표시되기도 하지만... 기업에게 서비스하는 상품이 이런 문제가 있으면 안되겠죠?
빅데이터 분석을 위해서는 새로운 방법이 필요한데, 구글에서 제공하는 빅쿼리가 하나의 선택지가 될 수 있습니다. 하나의 선택지라고 말하는 이유는, 사실 빅데이터를 취급할 수 있는 여러가지의 방법이 있기 때문입니다.
구글 클라우드 서비스에만 해도 빅쿼리 말고도 유사한 결과를 만들 수 있는 서비스들이 있습니다. 예를 들어, Cloud SQL 도 Datastudio 에 연결할 수 있습니다.
하지만 이 포스트 초반부에서 이야기한 셀 부족의 문제를 해결하는 가장 간단한 방법은 빅쿼리를 꼽을 수 있을 것 같습니다. 데이터스튜디오와의 연결에서 BI 엔진을 적용하면 매우 빠른 로딩 속도를 보여주는 것도 큰 장점입니다. 
최근의 프로젝트 중 데이터의 규모가 스프레드시트 이상이거나, 연차별로 나누어서 관리할 필요성이 있으면 빅쿼리를 적용하고 있는데, 꽤 만족스럽습니다.
빅쿼리에 대해 간단하게 알아보시려면, 구글에서 제공하는 빅쿼리 하이라이트 동영상(영문)을 한 번 살펴보세요.
관련 포스팅
다음의 포스팅을 준비 중에 있습니다.
.png&blockId=26bb2d8a-486c-8027-aced-f867d97a157c)

